
آخر المواضيع المضافة

 النبات
الحيوان
الأحياء المجهرية
علم الأمراض
التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحياتية النانوية
علم الأجنة
الأحياء الجزيئي
علم وظائف الأعضاء
الغدد
المضادات الحيوية
النبات
الحيوان
الأحياء المجهرية
علم الأمراض
التقانة الإحيائية
التقنية الحيوية المكروبية
التقنية الحياتية النانوية
علم الأجنة
الأحياء الجزيئي
علم وظائف الأعضاء
الغدد
المضادات الحيوية| DNA Sequences Evolve by Mutation and a Sorting Mechanism |


|
|
Read More
Date: 25-12-2015
Date: 16-6-2021
Date: 4-5-2021
|
DNA Sequences Evolve by Mutation and a Sorting Mechanism
KEY CONCEPTS
-The probability of a mutation is influenced by the likelihood that the particular error will occur and the likelihood that it will be repaired.
-In small populations, the frequency of a mutation will change randomly and new mutations are likely to be eliminated by chance.
-The frequency of a neutral mutation largely depends on genetic drift, the strength of which depends on the size of the population.
-The frequency of a mutation that affects phenotype will be influenced by negative or positive selection.
Biological evolution is based on two sets of processes: the generation of genetic variation and the sorting of that variation in subsequent generations. Variation among chromosomes can be generated by recombination ; variation among sexually reproducing organisms results from the combined processes of meiosis and fertilization. Ultimately, however, variation among DNA sequences is a result of mutation.
Mutation occurs when DNA is altered by replication error or chemical changes to nucleotides, or when electromagnetic radiation breaks or forms chemical bonds, and the damage remains unrepaired at the time of the next DNA replication event . Regardless of the cause, the initial damage can be considered an “error.” In principle, a base can mutate to any of the other three standard bases, though the three possible mutations are not equally likely due to biases incurred by the mechanisms of damage and differences in the likelihood of repair of the damage.
For example, if mutation from one base to any of the other three is equally probable, transversion mutations (from a pyrimidine to a purine, or vice versa) would be twice as frequent as transition mutations (from one pyrimidine to another, or one purine to another). However, the observation is usually the opposite: Transitions occur roughly twice as frequently as transversions. This might be because (1) spontaneous transitional errors occur more frequently than transversional errors; (2) transversional errors are more likely to be detected and corrected by DNA repair mechanisms; or (3) both of these are true. Given that transversional errors result in distortion of the DNA duplex as either pyrimidines or purines are paired together, and that basepair geometry is used as a fidelity mechanism , it is less likely for a DNA polymerase to make a transversional error. The distortion also makes it easier for transversional errors to be detected by postreplication repair mechanisms. As shown in FIGURE 1., a basic model of mutation would be that the probabilities of transitions are equal (α), as are those of transversions (β), and that α > β. More complex models could have different probabilities for the individual substitution mutations, and could be tailored to individual taxonomic groups from actual data on mutation rates in those groups.
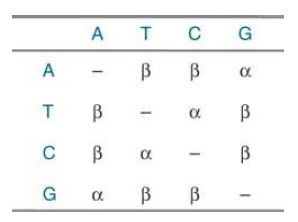
FIGURE 1. A simple model of mutational change in which α is the probability of a transition and β is the probability of a transversion.
Reproduced from MEGA (Molecular Evolutionary Genetics Analysis) by S. Kumar, K. Tamura, and J. Dudley. Used with permission of Masatoshi Nei, Pennsylvania State University.
If a mutation occurs in the coding region of a protein-coding gene, it can be characterized by its effect on the polypeptide product of the gene. A substitution mutation that does not change the amino acid sequence of the polypeptide product is a synonymous mutation; this is a specific type of silent mutation. (Silent mutations include those that occur in noncoding regions.) A nonsynonymous mutation in a coding region does alter the amino acid sequence of the polypeptide product, resulting in either a missense codon (for a different amino acid) or a nonsense (termination) codon. The effect of the mutation on the phenotype of the organism will influence the fate of the mutation in subsequent generations.
Mutations in genes other than those encoding polypeptides and mutations in noncoding sequences can, of course, also be subject to selection. In noncoding regions, a mutational change can alter the regulation of a gene by directly changing a regulatory sequence or by changing the secondary structure of the DNA in such a way that some aspect of the gene’s expression (such as transcription rate, RNA processing, or mRNA structure influencing translation rate) is affected. However, many changes in noncoding regions might be selectively neutral mutations, having no effect on the phenotype of the organism.
If a mutation is selectively neutral or near neutral, its fate is predictable only in terms of probability. The random changes in the frequency of a mutational variant in a population are called genetic drift; this is a type of “sampling error” in which, by chance, the offspring genotypes of a particular set of parents do not precisely match those predicted by Mendelian inheritance. In a very large population, the random effects of genetic drift tend to average out,
so there is little change in the frequency of each variant. However, in a small population, these random changes can be quite significant and genetic drift can have a major effect on the genetic variation of the population. FIGURE 2. shows a simulation comparing the random changes in allele frequency for seven populations of 10 individuals each with those of seven populations of 100 individuals each. Each population begins with two alleles, each with a frequency of 0.5. After 50 generations, most of the small populations have lost one or the other allele (p = 1 means only one allele is left and p = 0 means only the other allele is left), whereas the large populations have retained both alleles (though their allele frequencies have randomly drifted from the original 0.5).

FIGURE 2. The fixation or loss of alleles by random genetic drift occurs more rapidly in populations of 10 (a) than in populations of 100. (b) p is the frequency of one of two alleles at a locus in the population.
Data courtesy of Kent E. Holsinger, University of Connecticut (http://darwin.eeb.uconn.edu).
Genetic drift is a random process. The eventual fate of a particular variant is not strictly predictable, but the current frequency of the variant is a measure of the probability that it will eventually be fixed (replacing all other variants) in the population. In other words, a new mutation (with a low frequency in a population) is very likely to be lost from the population by chance. However, if by chance it becomes more frequent, it has a greater probability of being retained in the population. Over the long term, a variant might either be lost from the population or fixed, but in the short term there might be randomly fluctuating variation for a particular locus, especially in smaller populations where fixation or loss occurs more quickly.
On the other hand, if a new mutation is not selectively neutral and does affect phenotype, natural selection will play a role in its increase or decrease in frequency in the population. The speed of its frequency change will partly depend on how much of an advantage or disadvantage the mutation confers to the organisms that carry it. It will also depend on whether it is dominant or recessive; in general, because dominant mutations are “exposed” to natural selection when they first appear, they are affected by selection more rapidly.
Mutations are random with regard to their effects, and thus the common result of a nonneutral mutation is for the phenotype to be negatively affected, so selection often acts primarily to eliminate new mutations (though this might be somewhat delayed in the likely event that the mutation is recessive). This is called negative (or purifying) selection (see the chapter titled The Interrupted Gene).
The overall result of negative selection is for there to be little variation within a population as new variants are generally eliminated. More rarely, a new mutation might be subject to positive selection (see the chapter titled The Interrupted Gene) if it happens to confer an advantageous phenotype. This type of selection will also tend to reduce variation within a population, as the new mutation eventually replaces the original sequence, but can result in greater variation between populations, provided they are isolated from one another, as different mutations occur in these different populations.
The question of how much observed genetic variation in a population or species (or the lack of such variation) is due to selection and how much is due to genetic drift is a long-standing one in population genetics. In the next section, we look at some ways that selection on DNA sequences might be detected by testing for significant differences from the expectations of evolution of neutral mutations.

|
|
|
|
تفوقت في الاختبار على الجميع.. فاكهة "خارقة" في عالم التغذية
|
|
|
|
|
|
|
أمين عام أوبك: النفط الخام والغاز الطبيعي "هبة من الله"
|
|
|
|
|
|
|
المجمع العلمي ينظّم ندوة حوارية حول مفهوم العولمة الرقمية في بابل
|
|
|
















