The importance of hapax legomena
According to Baayen (1992), if you want to study morphological productivity, it is important to study hapax legomena, words that appear only once in a given corpus, preferably a large one. Why? If you adhere to the theory discussed immediately above, then a productive rule is like a machine that spins out words, throws them into the air, and doesn’t bother to keep track of them. Words that appear only once in a large corpus are more likely than words that are used repeatedly to have been formed by a productive rule.
If this seems counterintuitive to you, then think of it in terms of concrete examples. If you look in the dictionary, you probably won’t find giggle-gaggle. But it does not sound odd, because semi-reduplicatives like this are common in English: chitchat, jingle-jangle, flip-flop, zigzag. If giggle-gaggle fell out as a hapax legomenon in a large corpus, it would be precisely because it follows a productive pattern, and speakers who use it can create it on the fly. Memorized words, ones that are not created on the fly but are stored in the lexicon, are more likely to recur in a large corpus. So in a large corpus, we would expect to find multiple examples of words like monitor, third, or get. We are not claiming that words that follow a productive pattern have to be hapax legomena – we would also expect to find multiple examples of inflected forms of common words, like argues or arguing. We are saying only that if a word is a hapax legomenon, it is more likely to have been formed by a productive rule.
If you take a huge corpus – say, 30, 50, or 100 million words – and look for words that occur only once, this will be a very good indicator of productivity. The formula that Baayen proposes is quite simple: pro ductivity 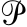 is equal to the number of words occurring only once in a corpus divided by the total number of tokens of words of the same morphological type:
is equal to the number of words occurring only once in a corpus divided by the total number of tokens of words of the same morphological type:
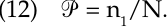
For example, if we are considering the type X-ness (e.g., redness), then we look for words that occur only once in our corpus (perhaps decidedness), and we divide the total number of such once-only words by the total number of occurrences of the type X-ness in our corpus. This will be our measure of the productivity of the type X-ness in our corpus. The larger and more representative of the language the corpus is, the closer this  number comes to the actual productivity of the pattern in the language.
number comes to the actual productivity of the pattern in the language.
Baayen’s formula does not take into consideration how many different types of words there are, only the ratio of hapax legomena to actual words. If you find a high ratio of words that occur only once in a given pattern to the total number of words in the pattern, you demonstrate productivity. This is a formula with reasonable predictability and a technique for indirectly gaining access to what kind of linguistic knowledge speakers possess.
There are some caveats to Baayen’s formula, as pointed out by Bauer (2001), who applied the formula to the Wellington Corpus of Written New Zealand English. In that corpus, the suffix -iana occurs only once, in the word Victoriana. If we apply the formula, the number of hapax legomena is one and the total number of tokens in the corpus is also one, so -iana appears to be totally productive – an apparently absurd result. This doesn’t reflect a problem with Baayen’s formula, as Bauer notes. Instead, the problem lies with the relatively small sample size.
The Wellington Corpus of Written New Zealand English contains not much more than a million words and only one example of the suffix -iana. This is not enough for our purposes. (Baayen’s original corpus was about 18 times larger.) It’s also important to keep in mind that the numbers we get by applying Baayen’s formula cannot be compared across corpora of different sizes. The same affix might garner different  results depending on the corpora used. This doesn’t invalidate the formula. It comes about because the
results depending on the corpora used. This doesn’t invalidate the formula. It comes about because the  value produced is relative to the size of the corpus.
value produced is relative to the size of the corpus.





















